您现在的位置是:网站首页> 编程资料编程资料
Python数据挖掘Pandas详解_python_
![]() 2023-05-26
484人已围观
2023-05-26
484人已围观
简介 Python数据挖掘Pandas详解_python_
1 DataFrame
- Pandas=panel+data+analysis
- 专门用于数据挖掘的开源Python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
核心数据结构
- DataFrame (是series的容器,一般二维)
- Panel(是dataframe的容器,三维)
- Series(一维)
1.1 构造dataframe 利用DataFrame函数
- 索引:行索引-index,横向索引;列索引-columns,纵向索引
- 值:values,利用values即可直接获得去除索引的数据(数组)
- shape:表明形状 (形状不含索引的行列)
- T:行列转置
DataFrame是一个既有行索引又有列索引的二维数据结构
import numpy as np import pandas as pd a=np.ones((2,3)) b=pd.DataFrame(a) print(a) print(b)
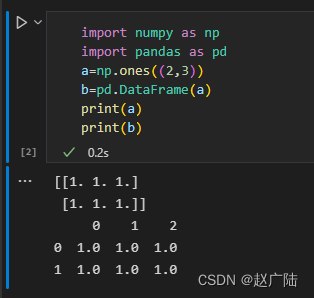
如图,生成的打他frame是一个二维表,由于没有指定索引,因此默认行列索引为数字序号
1.2 常用操作(设置索引)
1.获取局部展示
b.head()#默认展示前5行,可在head()加入数字,展示前几行 b.tail()#默认展示后5行,可在tail()加入数字,展示后几行
2.获取索引和值
import numpy as np # 创建一个符合正态分布的10个股票5天的涨跌幅数据 stock_change = np.random.normal(0, 1, (10, 5)) pd.DataFrame(stock_change) #设置行列索引 stock = ["股票{}".format(i) for i in range(10)] date = pd.date_range(start="20200101", periods=5, freq="B")#这个是pandas中设置日期的 # 添加行列索引 data = pd.DataFrame(stock_change, index=stock, columns=date) print(data)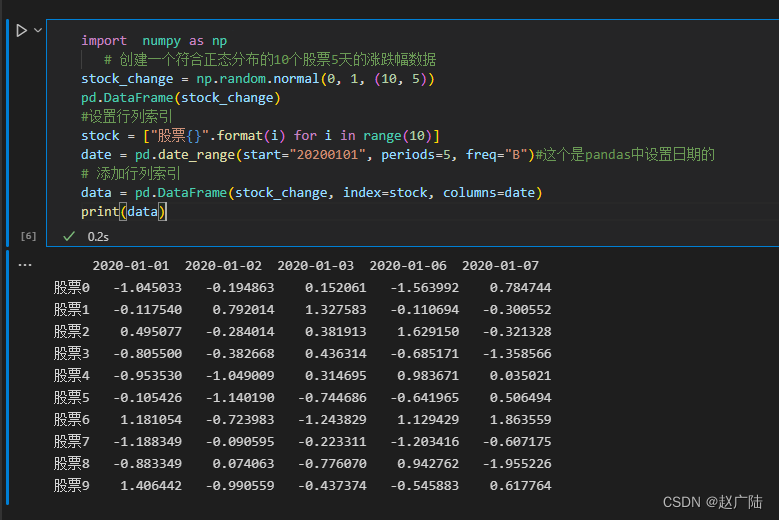
3.设置行列索引
# 创建一个符合正态分布的10个股票5天的涨跌幅数据 stock_change = np.random.normal(0, 1, (10, 5)) pd.DataFrame(stock_change) #设置行列索引 stock = ["股票{}".format(i) for i in range(10)] date = pd.date_range(start="20200101", periods=5, freq="B")#这个是pandas中设置日期的 # 添加行列索引 data = pd.DataFrame(stock_change, index=stock, columns=date) print(data) 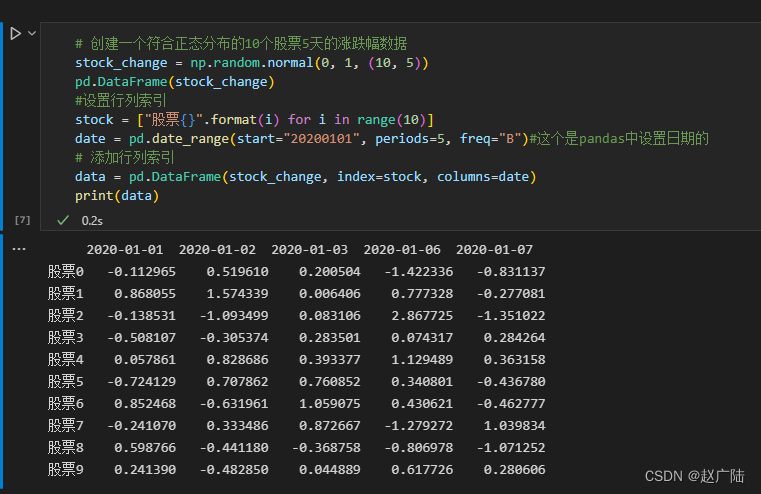
4.修改索引
#不能单独修改行列总某一个索引的值,可以替换整行或整列 例:b.index[2]='股票1' 错误 data.index=新行索引 #重设索引 data.reset_index(drop=False) #drop参数默认为False,表示将原来的索引替换掉,换新索引为数字递增,原来的索引将变为数据的一部分。True表示,将原来的索引删除,更换为数字递增。如下图

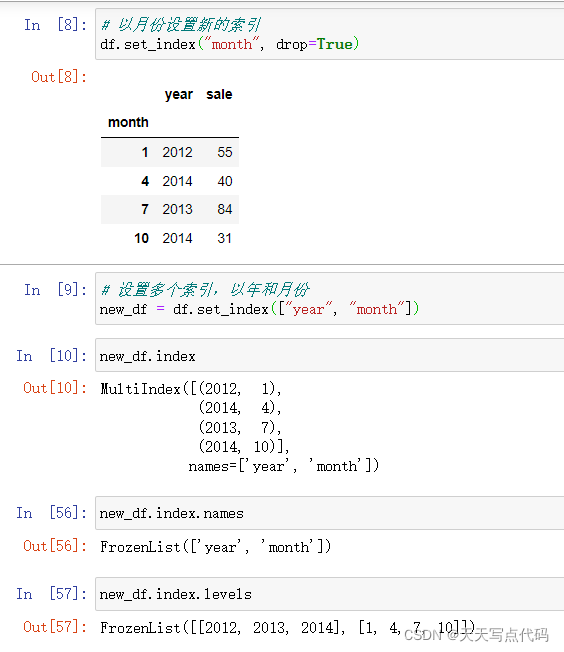
# 设置新索引 df = pd.DataFrame({'month': [1, 4, 7, 10], 'year': [2012, 2014, 2013, 2014], 'sale':[55, 40, 84, 31]}) # 以月份设置新的索引 df.set_index("month", drop=True) #见下图,即将原本数据中的一列拿出来作为index new_df = df.set_index(["year", "month"])# 设置多个索引,以年和月份 多个索引其实就是MultiIndex 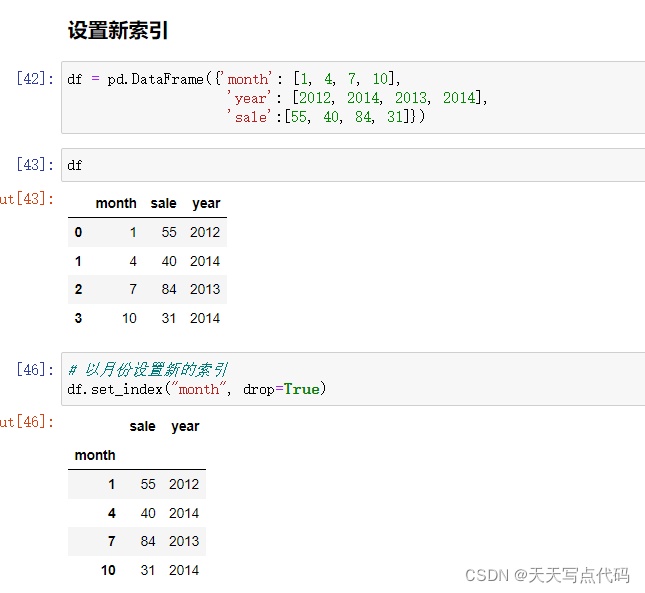
可以看到下面的new_df已经是multiIndex类型数据了。
有三级:index index.names index.levels
分别看各自的输出
1.3 MultiIndex与Panel
MultiIndex:多级或分层索引对象
Panel:
pandas.Panel(data=None,items=None,major_axis=None,minor_axis=None,copy=False,dtype=None)
存储3维数组的Panel结构
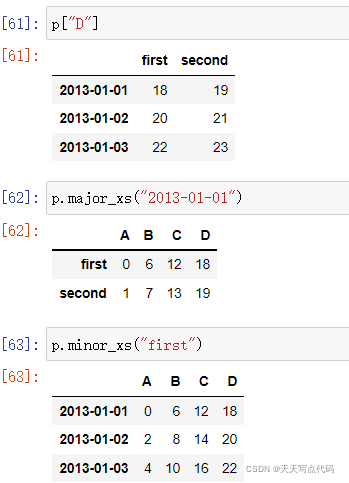
- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
- major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)。
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。 major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)。 minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
Pandas从版本0.20.0开始弃用,推荐的用于表示3D数据的方法是DataFrame上的MultiIndex方法
1.4 Series
带索引的一维数组
- index
- values
# 创建 pd.Series(np.arange(3, 9, 2), index=["a", "b", "c"]) # 或 pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000}) sr = data.iloc[1, :] sr.index # 索引 sr.values # 值 #####就是从dataframe中抽出一行或一列来观察 123456789102 基本数据操作
2.1 索引操作
data=pd.read_csv("./stock_day/stock_day.csv")#读入文件的前5行表示如下 ######利用drop删除某些行列,需要利用axis告知函数是行索引还是列索引 data=data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1) # 去掉一些不要的列 data["open"]["2018-02-26"] # 直接索引,但需要遵循先列后行 #####按名字索引利用.loc函数可以不遵循列行先后关系 data.loc["2018-02-26"]["open"] # 按名字索引 data.loc["2018-02-26", "open"] #####利用.iloc函数可以只利用数字进行索引 data.iloc[1][0] # 数字索引 data.iloc[1,0] # 组合索引 # 获取行第1天到第4天,['open', 'close', 'high', 'low']这个四个指标的结果 data.ix[:4, ['open', 'close', 'high', 'low']] # 现在不推荐用了 ###但仍可利用loc和iloc data.loc[data.index[0:4], ['open', 'close', 'high', 'low']] data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]2.2 赋值操作
data仍然是上图类型
data.open=100 data['open']=100 ###两种方式均可 data.iloc[1,0]=100 ###找好索引即可
2.3 排序
sort_values (比较values进行排序) sort_index (比较行索引进行排序,不行可以先转置简介对列排序)
data.sort_values(by="high", ascending=False) # DataFrame内容排序,ascending表示升序还是降序,默认True升序 data.sort_values(by=["high", "p_change"], ascending=False).head() # 多个列内容排序。给出的优先级进行排序 data.sort_index(ascending=True)###对行索引进行排序 #这里是取出了一列 “price_change”列,为serise,用法同上 sr = data["price_change"] sr.sort_values(ascending=False) sr.sort_index()
2.4 数学运算
布尔值索引
算术运算:直接利用运算符或者函数
#正常的加减乘除等的运算即可 data["open"] + 3 data["open"].add(3) # open统一加3 data.sub(100)# 所有统一减100 data - 100 (data["close"]-(data["open"])).head() # close减open
逻辑运算 :< ; > ; | ; & 利用逻辑符号或者函数query
# 例如筛选p_change > 2的日期数据 data[data["p_change"] > 2].head() # 完成一个多个逻辑判断, 筛选p_change > 2并且low > 15 data[(data["p_change"] > 2) & (data["low"] > 15)].head() data.query("p_change > 2 & low > 15").head()###等效于上一行代码 ###判断# 判断'turnover'列索引中是否有4.19, 2.39,将返回一列布尔值 data["turnover"].isin([4.19, 2.39])##如下图 利用布尔值索引,即利用一个布尔数组索引出True的数据
###判断# 判断'turnover'列索引中是否有4.19, 2.39,将返回一列布尔值 data["turnover"].isin([4.19, 2.39])##如下图 data[data["turnover"].isin([4.19, 2.39])] #这块就将返回turnover列布尔值为true的如下图,也就是筛选出turnover中值为4.19和2.39 ###布尔值索引是一个很方便的数据筛选操作,比如: data[data["turnover"]>0.1] #也将筛选出turnover列中大于0.1的整体data数据,并不是说只返回turnover相关数据,判断只是返回布尔索引,利用索引的是data数据
2.5 统计运算
data.describe() #将返回关于列的最值,均值,方差等多种信息 ##其实这里很多就和numpy相似了 data.max(axis=0)#返回最值 data.idxmax(axis=0) #返回最值索引
累计统计函数(累加,累乘等)
- cumsum 计算前1/2/3/…/n个数的和
- cummax 计算前1/2/3/…/n个数的最大值
- cummin 计算前1/2/3/…/n个数的最小值
- cumprod 计算前1/2/3/…/n个数的积
自定义运算
apply(func, axis=0)
func: 自定义函数
axis=0: 默认按列运算,axis=1按行运算
data.apply(lambda x: x.max() - x.min()) #这里的lambda x: x.max() - x.min()是lambda表达式,是函数的简单写法也可 def fx(data): return data.max()-data.min()
3 画图
3.1 pandas.DataFrame.plot
- x: label or position, default None
- y: label, position or list of label, positions, default None
- Allows plotting of one column versus another
- kind: str
- ‘line’: line plot(default)
- ''bar": vertical bar plot
- “barh”: horizontal bar plot
- “hist”: histogram
- “pie”: pie plot
- “scatter”: scatter plot
#更简易用matplotlib data.plot(x="v
相关内容
- Python标准库sys库常用功能详解_python_
- Python pandas DataFrame基础运算及空值填充详解_python_
- 解决Python报错问题[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE]_python_
- Python流程控制if条件选择与for循环_python_
- pandas使用fillna函数填充NaN值的代码实例_python_
- Python实现邮件自动下载的示例详解_python_
- python sklearn 画出决策树并保存为PDF的实现过程_python_
- Python轻量级搜索工具Whoosh的使用教程_python_
- Python实现读取HTML表格 pd.read_html()_python_
- Python和C语言利用栈分别实现进制转换_python_
点击排行
本栏推荐